2_naturalScenes
数据来源
数据来自kaggle Intel Image Classification ,通过[3,150,150]三通道,150像素宽度的正方形图片,判断图像内容属于六种中的哪一类
{‘buildings’ -> 0,
‘forest’ -> 1,
‘glacier’ -> 2,
‘mountain’ -> 3,
‘sea’ -> 4,
‘street’ -> 5 }
数据分析
数据是图片,所以要检查一下图片的大小格式是否符合规范
训练数据格式直方图
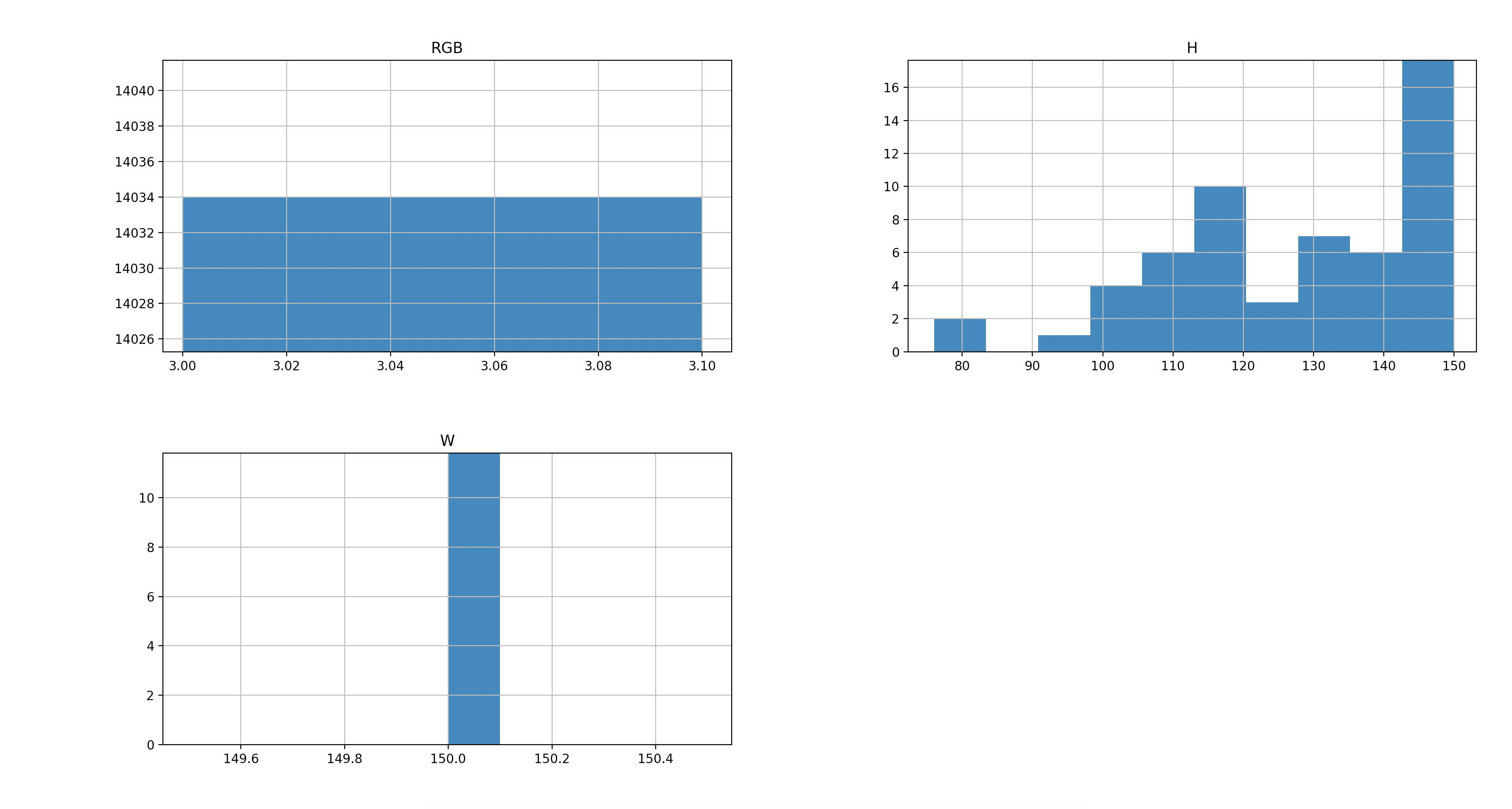
- 训练数据总共14034条,其中RGB三通道与图片宽度都符合要求,高度层面个别数据存在高度不够的问题,有问题的数据共39条,占比较少,这里就不做图像resize的处理,直接删除。
测试数据格式直方图
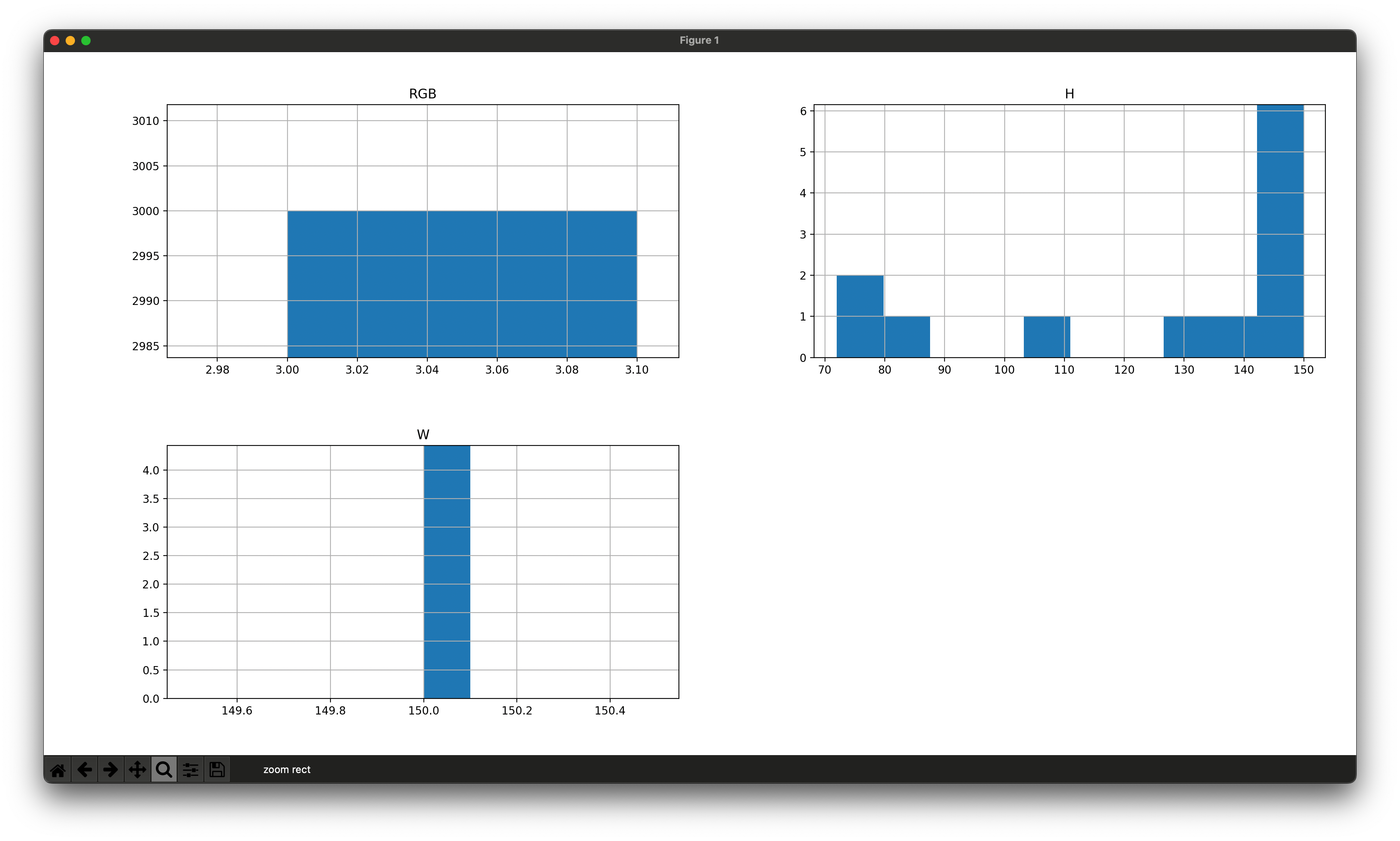
测试数据总共3000条,与训练数据一样,只有图片高度存在问题,有问题的数据共7条,占比较少直接删除。
20240621
特征工程
本次数据未做特征工程处理
模型确定
-
模型:选择最基本的$CNN$ $LeNet$ 网络作为本次测试模型,$CNN$部分设置3个卷积-池化块,全连接层设置为7层,$BATCHSIZE$设置为128
-
优化器:选择$Adadelta$优化器
-
损失函数:选择$CrossEntropyLoss$函数
完整代码
import sys
sys.path.append('/home/kureisersen/Documents/python3/ai/')
from SOURCE import *
class predData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_pred/seg_pred/'
self.file_dir = os.listdir(self.root_path)
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor
# {'buildings' -> 0,
# 'forest' -> 1,
# 'glacier' -> 2,
# 'mountain' -> 3,
# 'sea' -> 4,
# 'street' -> 5 }
class trainData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_train/seg_train/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[idx].split("/")[0]],dtype=torch.long)
class testData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_test/seg_test/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[idx].split("/")[0]],dtype=torch.long)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.n_hidden = 20
self.conv_layer = torch.nn.Sequential(
# input [batch_size,3,150,150]
torch.nn.Conv2d(3, 16, 3, stride=1, padding=1), # output [batch_size,16,150,150]
torch.nn.MaxPool2d(kernel_size=5, stride=5, padding=0), # output [batch_size,16,30,30]
torch.nn.Conv2d(16, 32, 3, stride=1, padding=1), # output [batch_size,32,30,30]
torch.nn.MaxPool2d(kernel_size=3, stride=3, padding=0), # output [batch_size,32,10,10]
torch.nn.Conv2d(32, 32, 3, stride=1, padding=1), # output [batch_size,32,10,10]
torch.nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # output [batch_size,32,5,5]
)
self.full_layer = torch.nn.Sequential(
torch.nn.Linear(32*5*5,self.n_hidden), # 1
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 2
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 3
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 4
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 5
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 6
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,6)
)
def forward(self, input):
out = self.conv_layer(input)
out = out.view(input.size(0),-1)
out = self.full_layer(out)
return out
if __name__ == '__main__':
BATCH_SIZE = 128
# pred_loader = DataLoader(dataset=predData(), batch_size=BATCH_SIZE,drop_last=True)
train_loader = DataLoader(dataset=trainData(), batch_size=BATCH_SIZE, shuffle=True,drop_last=True,num_workers=28,pin_memory=True)
# test_loader = DataLoader(dataset=testData(), batch_size=BATCH_SIZE,drop_last=True)
net = Net().cuda()
# train model
lossFun = torch.nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adadelta(net.parameters())
for i in range(2000):
loss_sum = 0
accuracy = 0
print('--------第{}轮--------'.format(i))
for idx,(data,lable) in enumerate(train_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
# print(y_pred,lable)
loss = lossFun(y_pred,lable)
# print(y_pred)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item()
accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
# if(idx%100==0):
# print("第{}次数据,loss为{}".format(idx,loss.item()))
print('第{}轮--平均loss值{}--平均正确率{}'.format(i,loss_sum/len(train_loader),accuracy/len(train_loader)))
训练结果
模型在训练集中的正确率稳定在99%,在测试集中的正确率稳定在75%,很明显模型过拟合了,下面针对这个问题改进一下
20240625
改进思路
过拟合问题比较常见,改进思路有以下几种:
- 缩小模型规模
- 在模型中增加BN层
- 在全连接网络中增加$Dropout$操作
- 增加训练数据
- 正则化
在改进过程中,分别对上述做法进行了尝试,下面描述一下不同方法的效果
- 缩小模型规模
- 模型确实没有了过拟合的特征,但是整体正确率变差,也并没有解决测试集与训练集正确率差距大的问题,这种操作在当前场景下不是很适用。
- 在全连接网络中增加$Dropout$操作
- 同等规模下模型训练速度变慢,需要迭代更多轮才能达到相同效果,但是依然没有解决过拟合问题。并且这种方法的适用性比较差,最新的模型中大都抛弃了这种方法。
- 在模型中增加BN层
- 有一定效果,模型在前几轮迭代中可以达到比较高的正确率,但是达到瓶颈期后的正确率降低
- 增加训练数据
- 在图片识别中可以使用图形变化,将图片旋转不同角度,来达到增加训练数据的目的,这种方法在实际使用过程中相对可行。下面实际看一下效果
特征工程
- 通过$transforms$随机水平翻转图片、随机旋转测试图片,以此增加测试数据
模型确定
-
模型:选择最基本的$CNN$ $LeNet$ 网络作为本次测试模型,$CNN$部分设置3个卷积-池化块,全连接层设置为7层,$BATCHSIZE$设置为128
-
优化器:选择$Adadelta$优化器
-
损失函数:选择$CrossEntropyLoss$函数
完整代码
import sys
sys.path.append('/home/kureisersen/Documents/python3/ai/')
from SOURCE import *
class predData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_pred/seg_pred/'
self.file_dir = os.listdir(self.root_path)
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor
# {'buildings' -> 0,
# 'forest' -> 1,
# 'glacier' -> 2,
# 'mountain' -> 3,
# 'sea' -> 4,
# 'street' -> 5 }
class trainData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_train/seg_train/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)*5
def __getitem__(self, idx):
integer = int(idx/5)
# remainder = idx & 4
image_path = self.root_path + self.file_dir[integer]
img_jpg = Image.open(image_path).convert('RGB')
transforms_comp = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(60),
transforms.ToTensor(),
])
img_tensor = transforms_comp(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[integer].split("/")[0]],dtype=torch.long)
class testData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_test/seg_test/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[idx].split("/")[0]],dtype=torch.long)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.n_hidden = 20
self.conv_layer = torch.nn.Sequential(
# input [batch_size,3,150,150]
torch.nn.Conv2d(3, 16, 3, stride=1, padding=1), # output [batch_size,16,150,150]
torch.nn.MaxPool2d(kernel_size=5, stride=5, padding=0), # output [batch_size,16,30,30]
torch.nn.Conv2d(16, 32, 3, stride=1, padding=1), # output [batch_size,32,30,30]
torch.nn.MaxPool2d(kernel_size=3, stride=3, padding=0), # output [batch_size,32,10,10]
torch.nn.Conv2d(32, 32, 3, stride=1, padding=1), # output [batch_size,32,10,10]
torch.nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # output [batch_size,32,5,5]
)
self.full_layer = torch.nn.Sequential(
torch.nn.Linear(32*5*5,self.n_hidden), # 1
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 2
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 3
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 4
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 5
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 6
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,6)
)
def forward(self, input):
out = self.conv_layer(input)
out = out.view(input.size(0),-1)
out = self.full_layer(out)
return out
if __name__ == '__main__':
BATCH_SIZE = 128
# pred_loader = DataLoader(dataset=predData(), batch_size=BATCH_SIZE,drop_last=True)
train_loader = DataLoader(dataset=trainData(), batch_size=BATCH_SIZE, shuffle=True,drop_last=True,num_workers=28,pin_memory=True)
valid_loader = DataLoader(dataset=testData(), batch_size=BATCH_SIZE, shuffle=True, drop_last=True,num_workers=28,pin_memory=True)
net = Net().cuda()
# train model
lossFun = torch.nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adadelta(net.parameters())
for i in range(2000):
loss_sum = 0
accuracy = 0
print('--------第{}轮--------'.format(i))
for idx,(data,lable) in enumerate(train_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
# print(y_pred,lable)
loss = lossFun(y_pred,lable)
# print(y_pred)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item()
accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
# if(idx%100==0):
# print("第{}次数据,loss为{}".format(idx,loss.item()))
# print('第{}轮--平均loss值{}--平均正确率{}'.format(i,loss_sum/len(train_loader),accuracy/len(train_loader)))
valid_loss_sum = 0
valid_accuracy = 0
with torch.no_grad():
for idx,(data,lable) in enumerate(valid_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
loss = lossFun(y_pred,lable)
valid_loss_sum += loss.item()
valid_accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
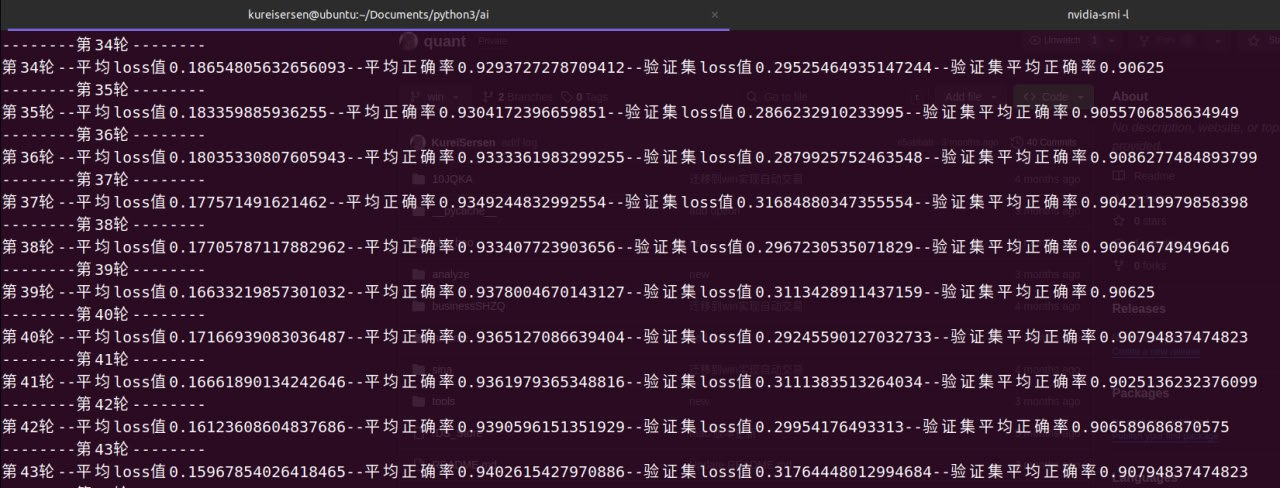
print('第{}轮--平均loss值{}--平均正确率{}--验证集loss值{}--验证集平均正确率{}'.format(i,loss_sum/len(train_loader),accuracy/len(train_loader),valid_loss_sum/len(valid_loader),valid_accuracy/len(valid_loader)))
训练结果
模型在训练集中的正确率稳定在86%,在测试集中的正确率稳定在83%,过拟合问题有一定好转,但是模型正确率不高
20240629
改进思路
正确率不高,期望通过增加模型复杂度解决,打算从$LeNet$换成$AlexNet$看看效果
特征工程
仍然是通过$transforms$随机水平翻转图片、随机旋转测试图片,以此增加测试数据,没有什么变化
模型确定
-
模型:选择$CNN$ $AlexNet$ 网络作为本次测试模型,$CNN$部分设置4个卷积-$RELU$-卷积-$RELU$-池化块,卷积的大趋势是减少全连接层,并逐步由卷积层代替,因此在该模型全连接层减少为3层,$BATCHSIZE$设置为128
-
优化器:选择$Adadelta$优化器
-
损失函数:选择$CrossEntropyLoss$函数
完整代码
import sys
sys.path.append('/home/kureisersen/Documents/python3/ai/')
from SOURCE import *
class predData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_pred/seg_pred/'
self.file_dir = os.listdir(self.root_path)
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor
# {'buildings' -> 0,
# 'forest' -> 1,
# 'glacier' -> 2,
# 'mountain' -> 3,
# 'sea' -> 4,
# 'street' -> 5 }
class trainData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_train/seg_train/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)*5
def __getitem__(self, idx):
integer = int(idx/5)
# remainder = idx & 4
image_path = self.root_path + self.file_dir[integer]
img_jpg = Image.open(image_path).convert('RGB')
transforms_comp = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(60),
transforms.ToTensor(),
])
img_tensor = transforms_comp(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[integer].split("/")[0]],dtype=torch.long)
class testData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_test/seg_test/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[idx].split("/")[0]],dtype=torch.long)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.n_hidden = 2000
self.conv_layer = torch.nn.Sequential(
# input [batch_size,3,150,150]
torch.nn.Conv2d(3, 64, 3, stride=1, padding=1), # output [batch_size,16,150,150]
torch.nn.ReLU(),
torch.nn.Conv2d(64, 64, 3, stride=1, padding=1), # output [batch_size,16,150,150]
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=5, stride=5, padding=0), # output [batch_size,16,30,30]
# torch.nn.ReLU(),
# torch.nn.BatchNorm2d(16),
torch.nn.Conv2d(64, 128, 3, stride=1, padding=1), # output [batch_size,32,30,30]
torch.nn.ReLU(),
torch.nn.Conv2d(128, 128, 3, stride=1, padding=1), # output [batch_size,16,150,150]
torch.nn.ReLU(),
# torch.nn.Conv2d(64, 64, 3, stride=1, padding=1), # output [batch_size,16,150,150]
# torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=3, stride=3, padding=0), # output [batch_size,32,10,10]
# torch.nn.ReLU(),
# torch.nn.BatchNorm2d(32),
torch.nn.Conv2d(128, 256, 3, stride=1, padding=1), # output [batch_size,32,10,10]
torch.nn.ReLU(),
torch.nn.Conv2d(256, 256, 3, stride=1, padding=1), # output [batch_size,16,150,150]
torch.nn.ReLU(),
# torch.nn.Conv2d(64, 64, 3, stride=1, padding=1), # output [batch_size,16,150,150]
# torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # output [batch_size,32,5,5]
torch.nn.Conv2d(256, 512, 3, stride=1, padding=1), # output [batch_size,32,10,10]
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, 3, stride=1, padding=1), # output [batch_size,16,150,150]
torch.nn.ReLU(),
# torch.nn.Conv2d(64, 64, 3, stride=1, padding=1), # output [batch_size,16,150,150]
# torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=5, stride=1, padding=0), # output [batch_size,32,5,5]
)
self.full_layer = torch.nn.Sequential(
torch.nn.Linear(512*1*1,self.n_hidden), # 1
torch.nn.ReLU(),
torch.nn.Linear(self.n_hidden,self.n_hidden), # 2
torch.nn.ReLU(),
# torch.nn.Linear(self.n_hidden,self.n_hidden), # 3
# torch.nn.ReLU(),
# torch.nn.Linear(self.n_hidden,self.n_hidden), # 4
# torch.nn.ReLU(),
# torch.nn.Dropout(0.5),
torch.nn.Linear(self.n_hidden,6)
)
def forward(self, input):
out = self.conv_layer(input)
out = out.view(input.size(0),-1)
out = self.full_layer(out)
return out
if __name__ == '__main__':
BATCH_SIZE = 128
# pred_loader = DataLoader(dataset=predData(), batch_size=BATCH_SIZE,drop_last=True)
train_loader = DataLoader(dataset=trainData(), batch_size=BATCH_SIZE, shuffle=True,drop_last=True,num_workers=28,pin_memory=True)
valid_loader = DataLoader(dataset=testData(), batch_size=BATCH_SIZE, shuffle=True, drop_last=True,num_workers=28,pin_memory=True)
net = Net().cuda()
# train model
lossFun = torch.nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adadelta(net.parameters())
for i in range(2000):
loss_sum = 0
accuracy = 0
print('--------第{}轮--------'.format(i))
for idx,(data,lable) in enumerate(train_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
# print(y_pred,lable)
loss = lossFun(y_pred,lable)
# print(y_pred)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item()
accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
# if(idx%100==0):
# print("第{}次数据,loss为{}".format(idx,loss.item()))
# print('第{}轮--平均loss值{}--平均正确率{}'.format(i,loss_sum/len(train_loader),accuracy/len(train_loader)))
valid_loss_sum = 0
valid_accuracy = 0
with torch.no_grad():
for idx,(data,lable) in enumerate(valid_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
loss = lossFun(y_pred,lable)
valid_loss_sum += loss.item()
valid_accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
print('第{}轮--平均loss值{}--平均正确率{}--验证集loss值{}--验证集平均正确率{}'.format(i,loss_sum/len(train_loader),accuracy/len(train_loader),valid_loss_sum/len(valid_loader),valid_accuracy/len(valid_loader)))
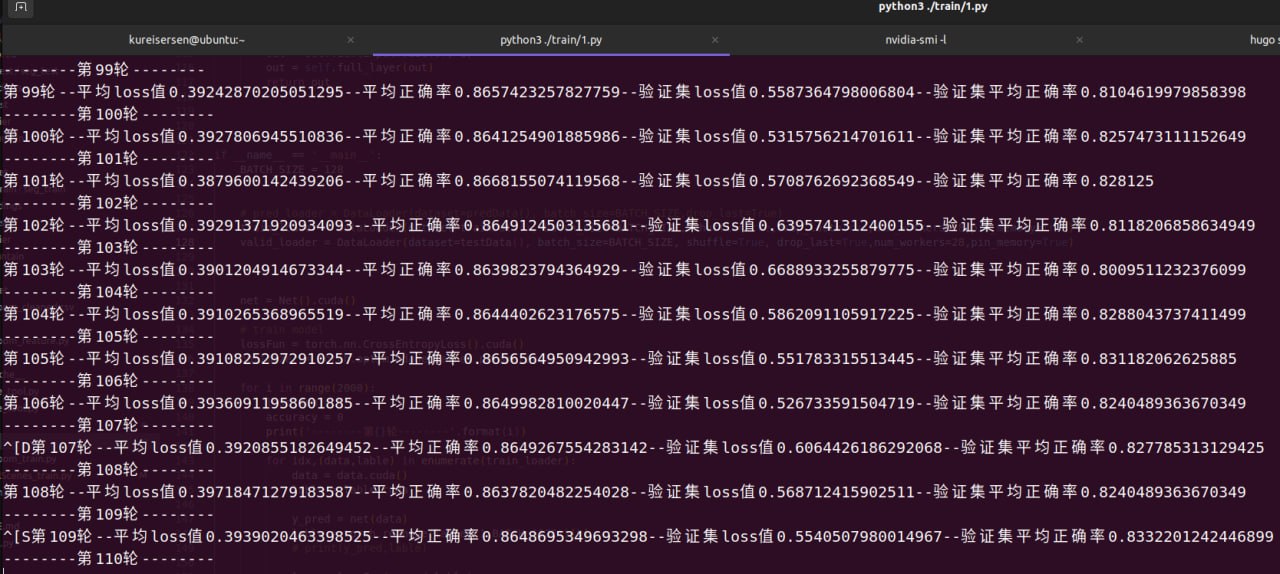
训练结果
模型在训练集中的正确率稳定在93%,在测试集中的正确率稳定在86%,模型正确率仍有提高的空间
20240713
改进思路
正确率不高,期望通过增加模型复杂度解决,打算从$AlexNet$换成$GoogLenet$看看效果
特征工程
原先随机旋转的方式会降低准确率,因此从随机旋转变成随机反转+随机放大
模型确定
-
模型:选择$CNN$ $GoogLeNet$ 网络作为本次测试模型,$CNN$部分设置5个$Inception$块,再尝试添加更多$Inception$块的过程中遇到了梯度消失的问题,后续可以c尝试将模型替换为$ResNet$解决该问题,在该模型全连接层减少为1层,$BATCHSIZE$设置为128
-
优化器:选择$Adadelta$优化器
-
损失函数:选择$CrossEntropyLoss$函数
完整代码
import sys
sys.path.append('/home/kureisersen/Documents/python3/ai/')
from SOURCE import *
class trainData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_train/seg_train/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)*5
def __getitem__(self, idx):
integer = int(idx/5)
# remainder = idx & 4
image_path = self.root_path + self.file_dir[integer]
img_jpg = Image.open(image_path).convert('RGB')
transforms_comp = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomResizedCrop(size=150, scale=(0.08, 1)),
# transforms.RandomRotation(60),
transforms.ToTensor(),
])
img_tensor = transforms_comp(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[integer].split("/")[0]],dtype=torch.long)
class testData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_test/seg_test/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[idx].split("/")[0]],dtype=torch.long)
class ConvRelu(torch.nn.Module):
def __init__(self,inTunnel, outTunnel, kernelSize, **kwargs):
super(ConvRelu,self).__init__()
self.conv_layer = torch.nn.Sequential(
torch.nn.Conv2d(inTunnel, outTunnel, kernelSize, **kwargs),
torch.nn.ReLU(),
)
def forward(self, input):
out = self.conv_layer(input)
return out
class Inception(torch.nn.Module):
def __init__(self,inTunnecl,FirstOutTunnel,SecOutTunnel,ThirOutTunnel,ForthOutTunnel):
super(Inception,self).__init__()
self.block1 = torch.nn.Sequential(
ConvRelu(inTunnecl,FirstOutTunnel,1,stride=1),
)
self.block2 = torch.nn.Sequential(
ConvRelu(inTunnecl,int(SecOutTunnel/2),1,stride=1),
ConvRelu(int(SecOutTunnel/2),SecOutTunnel,3,stride=1,padding=1),
)
self.block3 = torch.nn.Sequential(
ConvRelu(inTunnecl,int(ThirOutTunnel/2),1,stride=1),
ConvRelu(int(ThirOutTunnel/2),ThirOutTunnel,5,stride=1,padding=2),
)
self.block4 = torch.nn.Sequential(
torch.nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
ConvRelu(inTunnecl,ForthOutTunnel,1,stride=1),
)
def forward(self, input):
out1 = self.block1(input)
out2 = self.block2(input)
out3 = self.block3(input)
out4 = self.block4(input)
out = torch.cat((out1,out2,out3,out4),1)
return out
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv_layer = torch.nn.Sequential(
# Conv-Maxpool(忽略LocalRespNorm)
ConvRelu(3, 64, 7, stride=1, padding=3), # torch.Size([10, 64, 16, 16])
torch.nn.MaxPool2d(kernel_size=3, stride=3, padding=0), # torch.Size([10, 64, 7, 7])
# Conv-Conv-Maxpool(忽略LocalRespNorm)
ConvRelu(64, 64, 1),
ConvRelu(64, 128, 3, stride=1, padding=1), # torch.Size([10, 192, 7, 7])
torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1), # torch.Size([10, 192, 4, 4])
# Inception(3a)
Inception(128, 64, 96, 64, 32), # torch.Size([10, 256, 4, 4])
# Inception(3b)
Inception(256, 128, 192, 128, 64), # torch.Size([10, 480, 4, 4])
torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1), # torch.Size([10, 480, 2, 2])
# Inception(4a)
Inception(512, 256, 384, 256, 128), # torch.Size([10, 512, 2, 2])
# Inception(4b)
Inception(1024, 256, 384, 256, 128), # torch.Size([10, 512, 2, 2])
# # Inception(4c)
# Inception(512, 128, 192, 128, 64), # torch.Size([10, 512, 2, 2])
# # Inception(4d)
# Inception(512, 128, 192, 128, 64), # torch.Size([10, 528, 2, 2])
# # Inception(4e)
# Inception(528, 256, 160, 320, 32, 128, 128), # torch.Size([10, 832, 2, 2])
torch.nn.MaxPool2d(kernel_size=3, stride=3, padding=1), # torch.Size([10, 832, 1, 1])
# Inception(5a)
Inception(1024, 256, 384, 256, 128), # torch.Size([10, 832, 1, 1])
# # Inception(5b)
# Inception(1024, 256, 384, 256, 128), # torch.Size([10, 1024, 1, 1])
torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1), # torch.Size([10, 832, 1, 1])
torch.nn.AdaptiveAvgPool2d((1,1)),
)
self.full_layer = torch.nn.Sequential(
torch.nn.Linear(1024,6), # 1
# torch.nn.ReLU(),
# torch.nn.Linear(self.n_hidden,6)
)
def forward(self, input):
out = self.conv_layer(input)
out = out.view(input.size(0),-1)
out = self.full_layer(out)
return out
def printNet():
net = Net()
summary(net, (128, 3, 150, 150))
def startTrain():
BATCH_SIZE = 128
train_loader = DataLoader(dataset=trainData(), batch_size=BATCH_SIZE, shuffle=True,drop_last=True,num_workers=28,pin_memory=True)
valid_loader = DataLoader(dataset=testData(), batch_size=BATCH_SIZE, shuffle=True, drop_last=True,num_workers=28,pin_memory=True)
net = Net().cuda()
lossFun = torch.nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adadelta(net.parameters())
for i in range(2000):
loss_sum = 0
accuracy = 0
print('--------第{}轮--------'.format(i))
for idx,(data,lable) in enumerate(train_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
loss = lossFun(y_pred,lable)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item()
accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
valid_loss_sum = 0
valid_accuracy = 0
with torch.no_grad():
for idx,(data,lable) in enumerate(valid_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
loss = lossFun(y_pred,lable)
valid_loss_sum += loss.item()
valid_accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
print('第{}轮--平均loss值{}--平均正确率{}--验证集loss值{}--验证集平均正确率{}'.format(i,loss_sum/len(train_loader),accuracy/len(train_loader),valid_loss_sum/len(valid_loader),valid_accuracy/len(valid_loader)))
if __name__ == '__main__':
startTrain()
# printNet()
训练结果
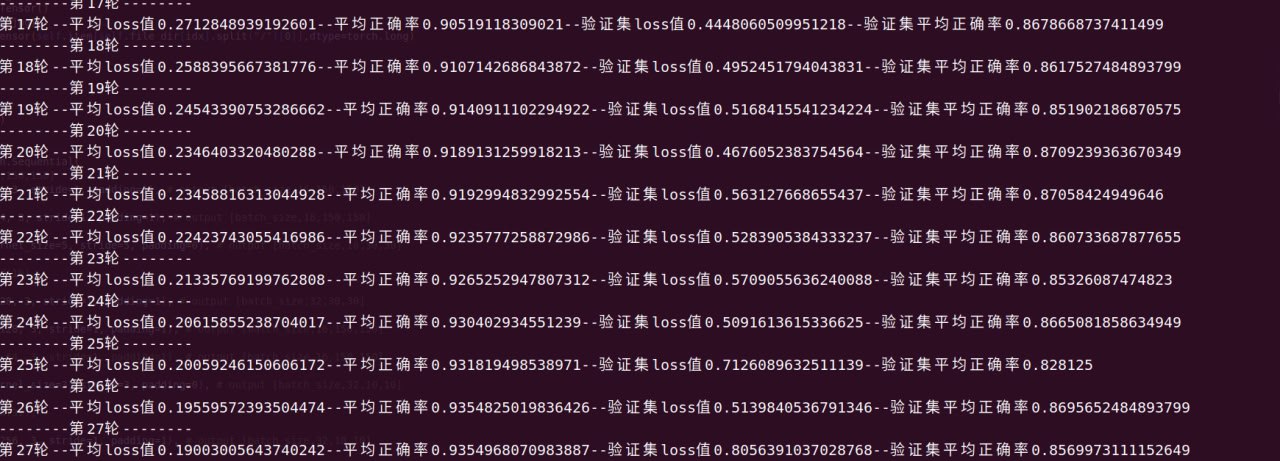
训练集正确率稳定在91%,预测集正确率稳定89%,预测集正确率进一步增大,同时训练集和预测集正确率差距减少,这种变化更多可能是数据特种工程带来的变化,也预示着后续动作只要提高训练集正确率就可以了。训练集在不断训练的过程中遇到了梯度消失的问题,该问题需要更换模型来改进。
20240719
改进思路
期望进一步提升模型在训练集和测试集的准确率,但是通过不断加深网络深度并没有起到积极的效果,打算从$GoogLenet$换成$Resnet$看看效果
特征工程
原先随机旋转的方式会降低准确率,因此从随机旋转变成随机反转+随机放大
模型确定
-
模型:选择$CNN$ $ResNet$ 网络作为本次测试模型,$CNN$部分设置5个$Resnet Block$块,在该模型全连接层为1层,$BATCHSIZE$设置为128
-
优化器:选择$Adadelta$优化器
-
损失函数:选择$CrossEntropyLoss$函数
完整代码
import sys
sys.path.append('/home/kureisersen/Documents/python3/ai/')
from SOURCE import *
class trainData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_train/seg_train/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)*5
def __getitem__(self, idx):
integer = int(idx/5)
# remainder = idx & 4
image_path = self.root_path + self.file_dir[integer]
img_jpg = Image.open(image_path).convert('RGB')
transforms_comp = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomResizedCrop(size=150, scale=(0.08, 1)),
# transforms.RandomRotation(60),
transforms.ToTensor(),
])
img_tensor = transforms_comp(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[integer].split("/")[0]],dtype=torch.long)
class testData(Dataset):
def __init__(self):
self.root_path = '/home/kureisersen/Documents/python3/ai/data/dateDir/natural_scenes/seg_test/seg_test/'
self.item = {'buildings':0,'forest':1,'glacier':2,'mountain':3,'sea':4,'street':5}
self.file_dir = []
for key, value in self.item.items():
file_arr = os.listdir(self.root_path + key + '/')
file_arr = [key + '/' + s for s in file_arr]
self.file_dir += file_arr
def __len__(self):
return len(self.file_dir)
def __getitem__(self, idx):
image_path = self.root_path + self.file_dir[idx]
img_jpg = Image.open(image_path).convert('RGB')
to_tensor = transforms.ToTensor()
img_tensor = to_tensor(img_jpg)
return img_tensor,torch.tensor(self.item[self.file_dir[idx].split("/")[0]],dtype=torch.long)
class Block(torch.nn.Module):
def __init__(self,in_channels, out_channels):
super(Block,self).__init__()
self.conv_layer = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, in_channels,1,stride=1),
torch.nn.BatchNorm2d(in_channels),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels, in_channels, 3,stride=2,padding=1),
torch.nn.BatchNorm2d(in_channels),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels ,out_channels,1, stride=1),
torch.nn.BatchNorm2d(out_channels),
)
self.extra_layer = torch.nn.Sequential(
torch.nn.Conv2d(in_channels ,out_channels,1, stride=2),
torch.nn.BatchNorm2d(out_channels),
)
def forward(self, input):
output = self.conv_layer(input)
output += self.extra_layer(input)
output = torch.nn.functional.relu(output)
return output
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv_layer = torch.nn.Sequential(
torch.nn.Conv2d(3, 64,7,stride=2,padding=3),
torch.nn.BatchNorm2d(64),
Block(64 ,128),
Block(128 ,512),
Block(512 ,512),
Block(512 ,1024),
Block(1024 ,1024),
# Block(in_channels ,out_channels),
# Block(in_channels ,out_channels),
torch.nn.AdaptiveAvgPool2d((1,1)),
)
self.full_layer = torch.nn.Sequential(
torch.nn.Linear(1024,6), # 1
)
def forward(self, input):
output = self.conv_layer(input)
output = output.view(input.size(0),-1)
output = self.full_layer(output)
return output
def printNet():
net = Net()
summary(net, (128, 3, 150, 150))
def startTrain():
BATCH_SIZE = 128
train_loader = DataLoader(dataset=trainData(), batch_size=BATCH_SIZE, shuffle=True,drop_last=True,num_workers=28,pin_memory=True)
valid_loader = DataLoader(dataset=testData(), batch_size=BATCH_SIZE, shuffle=True, drop_last=True,num_workers=28,pin_memory=True)
net = Net().cuda()
lossFun = torch.nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adadelta(net.parameters())
for i in range(2000):
loss_sum = 0
accuracy = 0
print('--------第{}轮--------'.format(i))
for idx,(data,lable) in enumerate(train_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
loss = lossFun(y_pred,lable)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item()
accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
valid_loss_sum = 0
valid_accuracy = 0
with torch.no_grad():
for idx,(data,lable) in enumerate(valid_loader):
data = data.cuda()
lable = lable.cuda()
y_pred = net(data)
lable = torch.reshape(lable,(1,BATCH_SIZE))[0]
loss = lossFun(y_pred,lable)
valid_loss_sum += loss.item()
valid_accuracy += (y_pred.argmax(1)==lable).sum()/BATCH_SIZE
print('第{}轮--平均loss值{}--平均正确率{}--验证集loss值{}--验证集平均正确率{}'.format(i,loss_sum/len(train_loader),accuracy/len(train_loader),valid_loss_sum/len(valid_loader),valid_accuracy/len(valid_loader)))
if __name__ == '__main__':
startTrain()
# printNet()
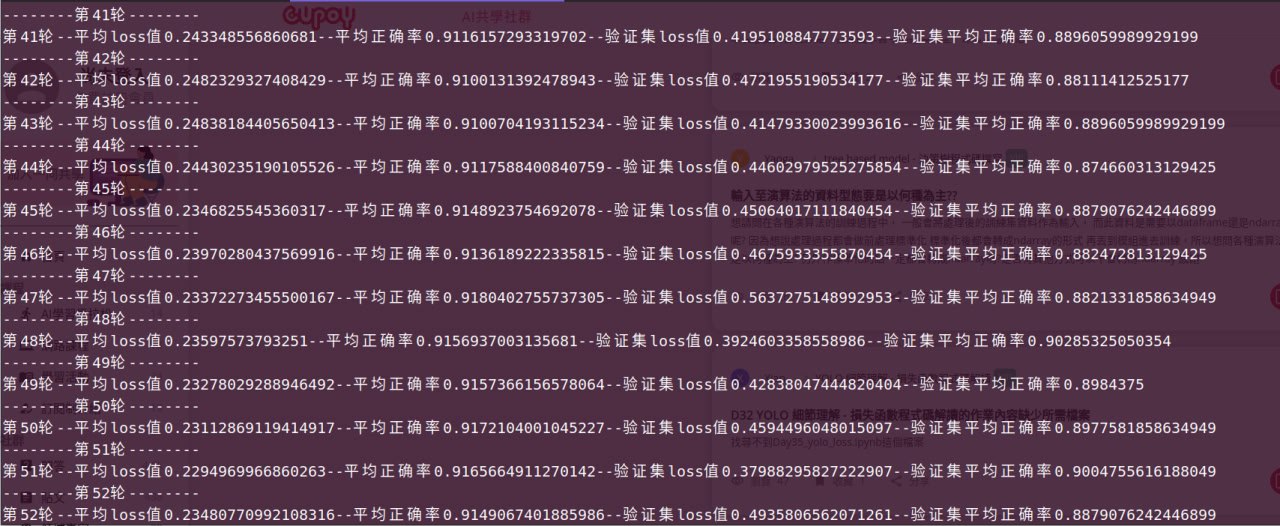
训练结果
训练集正确率稳定在94%,仍然有进一步上升的空间,观察到预测集正确率没有进一步提升的趋势,因此训练提前关停,预测集正确率稳定90%,提升了1个百分点。