4_santi
·
Edwin.Liang
数据来源
数据来自网上下载的中文<三体>小说,词向量方面的探索将以此为素材
20240903
数据处理
- 分词:使用$pkuseg$工具包进行分词处理,处理之后的文本单独存放为$santi_output$文件
- 去除标点符号等非中文字符
模型确定
- 模型:使用$gensim$库,调用$word2vec$感受一下初代词向量,其中词向量大小设置为$200$,窗口大小设置为$5$
完整代码
import sys
sys.path.append('/home/kureisersen/Documents/python3/ai/')
from SOURCE import *
def segmentation(input_dir,output_dir):
# pkuseg.test(input_dir, output_dir, nthread=28)
fo = open(output_dir,"r")
lines = []
for line in fo:
# print(line)
line_temp = line.split(" ")
words = []
for i in line_temp:
i = re.sub(r'[^\w\s]','',i)
i = i.strip()
if len(i) >0:
words.append(i)
if len(words) > 0:
lines.append(words)
# print(words)
return lines
if __name__ == '__main__':
lines = segmentation('/home/kureisersen/Documents/python3/ai/data/dateDir/santi.txt','/home/kureisersen/Documents/python3/ai/data/dateDir/santi_output.txt')
models = Word2Vec(sentences=lines, vector_size=200, window=5, min_count=3, workers=28)
print(models.wv.most_similar('叶文洁',topn=10))
训练结果
打印了与灵魂导师"叶文洁"相似度最高的前十个结果,感觉效果是有的,但是并没有那么好,继续探索.

20240920
环境搭建
- $glove$算法:使用stanfordnlp,代码是$C$语言写的。
- 用分词好的文档替换$demo.sh$中的$CORPUS$参数
- 执行一下$demo.sh$得到分词后的词向量结果文件$vectors.txt$
模型确定
- 模型:使用$glove$算法,看看和$word2vec$有什么区别,其中词向量大小设置为$50$,窗口大小设置为$15$
完整代码
import sys
sys.path.append('/home/kureisersen/Documents/python3/ai/')
from SOURCE import *
import numpy as np
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def read_vec(path):
word_vectors = {}
with open(path, 'r', encoding='utf-8') as f:
for line in f:
values = line.split()
word = values[0]
vector = np.array(values[1:], dtype='float32')
word_vectors[word] = vector
return word_vectors
if __name__ == '__main__':
word_vectors = read_vec("/home/kureisersen/Documents/c_cpp/glove/vectors.txt")
# similarity = cosine_similarity(word_vectors['叶文洁'], word_vectors['泰勒'])
for key in word_vectors:
similarity = cosine_similarity(word_vectors['叶文洁'], word_vectors[key])
if(similarity>0.658):
print(key,similarity)
# print(similarity)
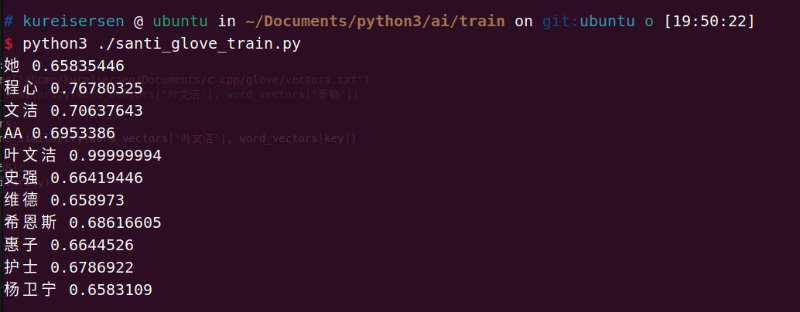
训练结果
“叶文洁”和“文洁”差的有点远,这点是没想到的,但是当前的前10个结果,都处在“人类”的范畴,没有出现之前$word2vec$“出去”的这种结果,勉勉强强.